파이썬을 이용하여 시가 총액 상위 10개의 가상 화폐 정보를 크롤링하는 것에 대해 알아보겠다.
크롤링을 할 사이트는 ‘CoinMarketCap.com’ 이며 크롤링 코드는 유튜브 채널 ‘Computer Science’를 참고하였다.
여기서 알아본 코드는 크롤링에 있어서 비교적 단순하고 쉬운편이어서 크롤링에 기본 개념을 이해하는데 많은 도움이 되었다.
먼저 파이썬을 이용하여 사이트 크롤링을 위해서는 다음의 라이브러리 모듈을 입력한다.
import pandas as pd
import requests
from bs4 import BeautifulSoup
파이썬 크롤링을 할 때에 대표적으로 사용하는 모듈은 두 가지가 있는데 하나는 여기서 사용한 BeautifulSoup이 있고 다른 한 가지는 Selenium이 있다.
BeautifulSoup은 html과 xml 문서를 파싱하기 위한 패키지이며 Selenium은 이와는 좀 다르게 웹 브라우저를 이용하며 사이트에서 자동적으로 제어가 가능하다는 차이가 있다.
그래서 Selenium은 웹 브라우저의 드라이브를 설치해야 한다.
이렇게만 비교하면 Selenium이 BeautifulSoup 보다 훨씬 유용할 것으로 생각되나 대신 Selenium은 라이브러리가 무겁고 크롤링이 자주 막힐 수 있는 단점이 있다고 한다.
일단 여기서는 간단한 예제로 BeautifulSoup의 기본적인 동작을 알아보고 다음에 Selenium에 대해서도 공부해보도록 하겠다.
여기서 크롤링 할 정보는 가상 화폐 이름과 시가 총액, 가격, 유통 공급량, 그리고 가상 화폐의 심볼이다.
아래는 이러한 정보를 크롤링하여 담아둘 빈 리스트와 크롤링된 데이터를 정리하기 위해 빈 DataFrame을 만드는 것이다.
crypto_name_list = []
crypto_market_cap_list = []
crypto_price_list = []
crypto_circulating_supply_list = []
crypto_symbol_list = []
df = pd.DataFrame()
아래의 코드는 크롤링할 웹 사이트 주소를 정의하고 html 문서를 파싱 할 준비를 한다.
URL = 'https://coinmarketcap.com/ko/historical/20220106/'
webpage = requests.get(URL)
soup = BeautifulSoup(webpage.text, 'html.parser')
이제 크롤링을 할 웹 페이지에 가서 페이지의 소스 코드를 분석해야 한다.
CoinMarketCap 사이트에서 과거의 가상 화폐 정보를 볼 수 있는 ‘과거 스냅샷’ 페이지로 간 후 가장 최근인 2022년 1월 2일 자로 들어가서 F12를 누른다.
소스 코드를 보면 아래의 그림처럼 정보는 'table'로 되어있는 곳 하부에 있으며 각 ‘tr’ 태그로 정의되어 있다.
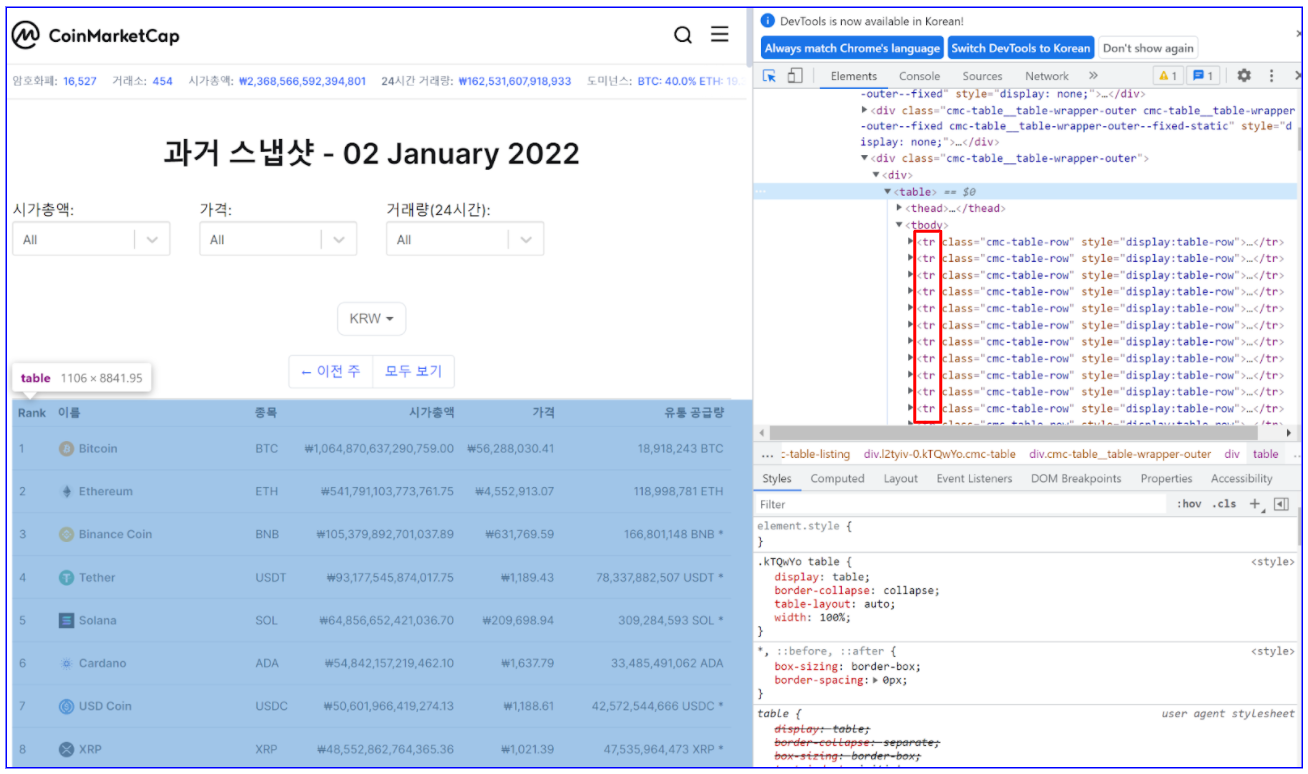
이 ‘tr’ 태그의 정보 중 class를 정의하여 해당하는 모든 정보를 찾는 코드는 다음과 같다.
tr = soup.find_all('tr', attrs={'class': 'cmc-table-row'})
하나의 'tr' 태그에 한 가상 화폐에 대한 이름과 시가 총액, 유통 공급량, 가격 등의 정보를 담고 있다.
각 가상 화폐의 순서는 시가 총액 순으로 되어 있으므로 이 'tr' 태그를 처음부터 10개까지만 크롤링하면 시가 총액 상위 10개의 가상 화폐에 대한 정보를 크롤링하는 것이다.
다음의 코드는 이러한 수행을 위한 내용이다.
count=0
for row in tr:
if count == 10:
break;
count = count+1
name_column = row.find('td', attrs={'class': 'cmc-table__cell cmc-table__cell--sticky cmc-table__cell--sortable cmc-table__cell--left cmc-table__cell--sort-by__name'})
crypto_name = name_column.find('a', attrs={'class': 'cmc-table__column-name--name cmc-link'}).text.strip()
crypto_market_cap = row.find('td', attrs={'class': 'cmc-table__cell cmc-table__cell--sortable cmc-table__cell--right cmc-table__cell--sort-by__market-cap'}).text.strip()
crypto_price = row.find('td', attrs={'class': 'cmc-table__cell cmc-table__cell--sortable cmc-table__cell--right cmc-table__cell--sort-by__price'}).text.strip()
crypto_circulating_supply_and_symbol = row.find('td', attrs={'class': 'cmc-table__cell cmc-table__cell--sortable cmc-table__cell--right cmc-table__cell--sort-by__circulating-supply'}).text.strip()
crypto_circulating_supply = crypto_circulating_supply_and_symbol.split(' ')[0]
crypto_symbol = crypto_circulating_supply_and_symbol.split(' ')[1]
crypto_name_list.append(crypto_name)
crypto_market_cap_list.append(crypto_market_cap)
crypto_price_list.append(crypto_price)
crypto_circulating_supply_list.append(crypto_circulating_supply)
crypto_symbol_list.append(crypto_symbol)
for 문을 사용하여 하나씩 'tr' 태그 안의 필요 정보를 크롤링하고 count가 10이 되면 멈추게 된다.
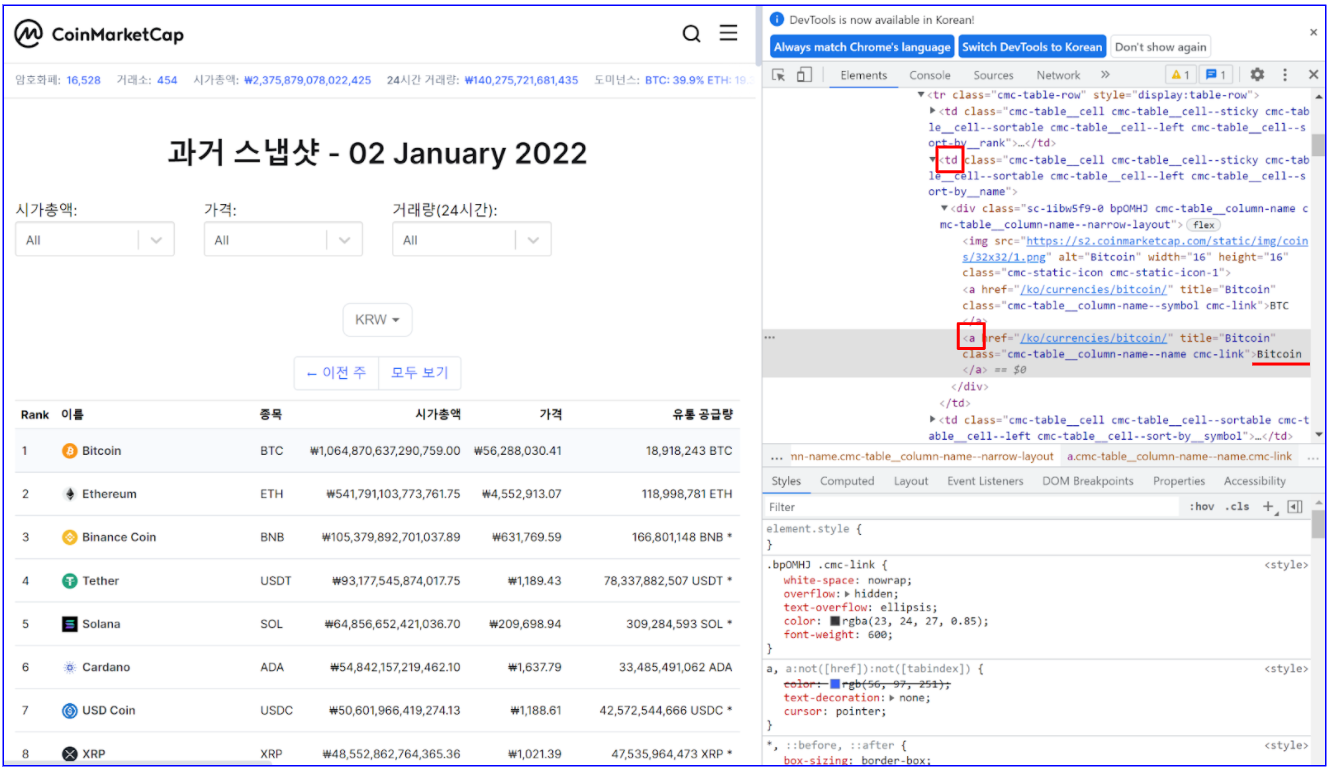
가상 화폐의 이름을 크롤링하는 것만 예를 들어 보면, 아래의 그림과 같이 가상 화폐 이름 Bitcoin은 ‘td’ 태그 아래 ‘a’ 태그에 있다.
그러므로 ‘name_column’ 변수에 'td' 태그의 class 특성을 정의한 정보를 저장하고 이 안에서 다시 ‘a’ 태그와 해당 class 정의를 하여 크롤링하면 가상 화폐 이름인 ‘Bitcoin’만 ‘cypto_name’ 변수에 저장된다.
이렇게 열 번에 걸쳐 크롤링된 정보는 ‘crypto_name_list에. append 함수를 통해 모두 저장된다.
다른 정보도 동일한 방법으로 크롤링된다.
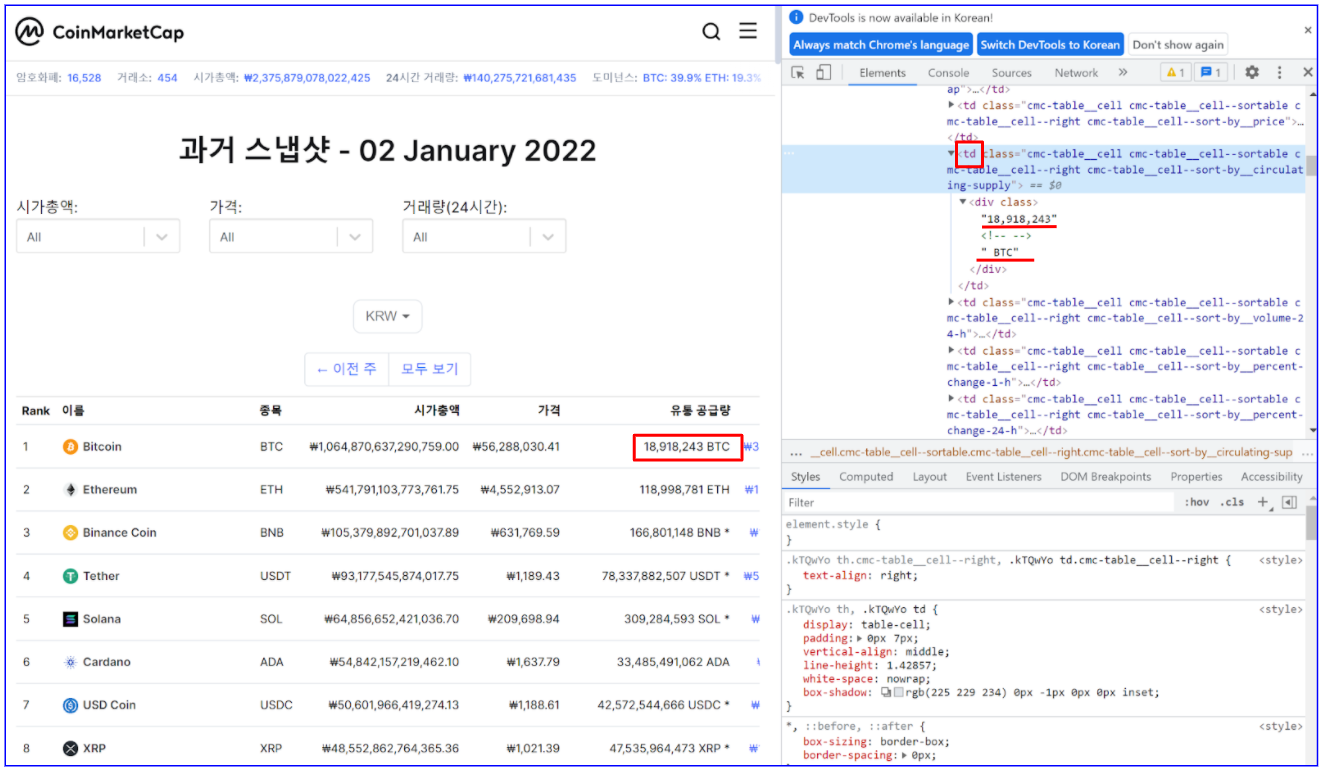
한 가지 약간 특이한 것은 마지막으로 크롤링되는 가상 화폐의 유통 공급량과 심볼이다.
다음의 그림과 같이 이 정보는 같은 ‘td’ 태그 안에 있으므로 한 번에 크롤링하여 이후 스페이스바를 기준으로한 .split 함수를 사용하여 두 정보로 나누고 각각의 변수에 저장하였다.
마지막은 앞에서 만든 빈 DataFrame을 통해 정보를 정리하는 것이다.
df['이름'] = crypto_name_list
df['시가 총액'] = crypto_market_cap_list
df['가격'] = crypto_price_list
df['유통 공급량'] = crypto_circulating_supply_list
df['심볼'] = crypto_symbol_list
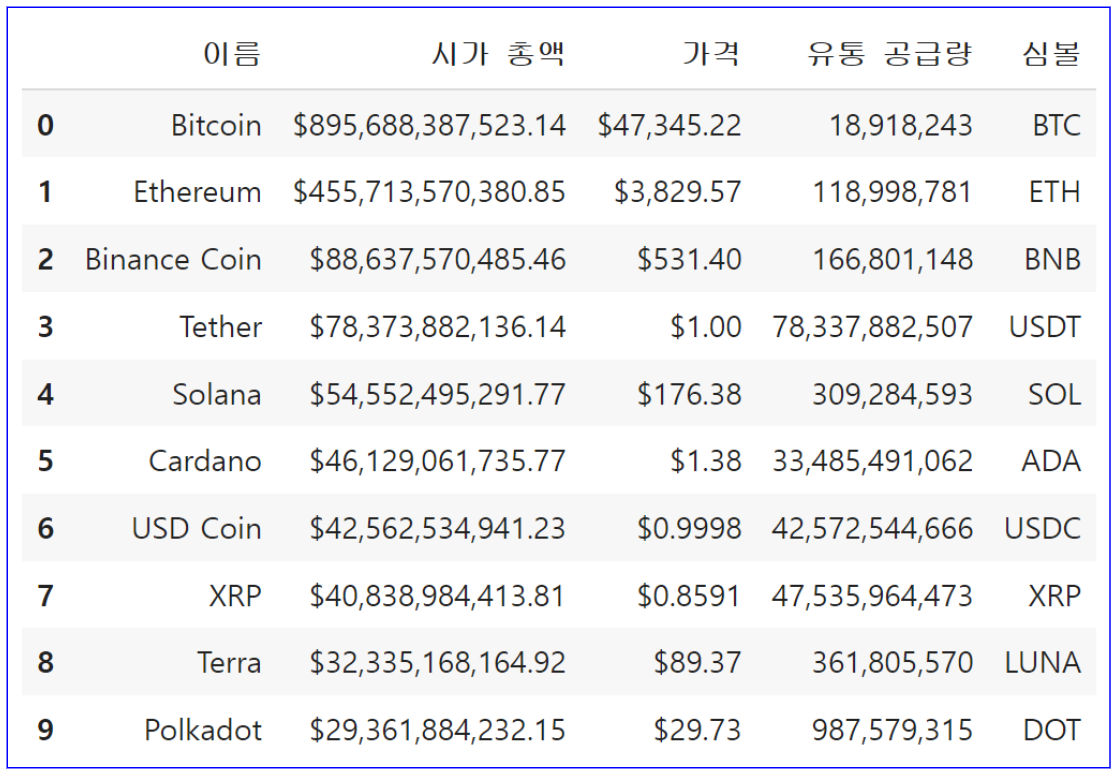
이렇게 크롤링된 결과는 아래와 같다.
다른 날짜의 정보를 크롤링하려면 앞에서 URL 주소를 해당하는 날짜의 웹페이지 URL로 변경한 후 실행시키면 된다.
여기까지 파이썬 BeautifulSoup을 이용하여 시가 총액 상위 10개의 가상 화폐의 정보를 크롤링하는 것에 대해 알아봤다.
다음에는 좀 더 다이내믹한 크롤링을 위해 Selenium을 공부하여 정리해볼 계획이다.
'Python' 카테고리의 다른 글
| 추세 지표와 변동성 지표의 조합을 통한 가상 화폐 매매 전략 (0) | 2022.02.20 |
|---|---|
| 파이썬을 이용한 주식 및 가상화폐 매매 전략 - CCI & Normalized MACD (4) | 2022.01.23 |
| 파이썬을 이용한 주식 및 가상 화폐 매매 전략 - Normalized MACD (3) | 2021.12.22 |
| 파이썬을 이용한 가상 화폐 매매 전략 - Stochastic RSI & EMA (0) | 2021.12.05 |
| QT Designer로 작성한 Python 프로그램 실행 파일 생성 시 에러 해결 (0) | 2021.11.30 |




댓글