파이썬 머신 러닝을 이용하여 기본적인 레이다 파라미터를 학습하고 특정 신호가 들어왔을 때 위협인지 아닌지를 판단하는 것에 대해 알아본다.
개 요
최신의 전자전 기술 흐름은 Cognitive Electronic Warfare 또는 우리말로 인지 전자전라 부르며 인공지능을 전자전 시스템에 적용하는 것이다.
Cognitive EW는 최신의 머신 러닝과 인공지능을 전자전 시스템에 적용하는 것이며, 이를 통해 기존의 위협 라이브러리 기반으로 작동하는 방식에서 벗어날 수 있다.
예를 들면, 위협 라이브러리에 포함되지 않는 미지의 신호를 수신하였을 때 기존의 학습을 통해 이 신호가 위협인지 여부를 판단하는 것이며 여기서 더 나아가 어떤 재밍 기법의 신호가 효과적인지 판단하여 대응할 수 있다.
기존의 시스템이라면 위협 라이브러리에 없으면 위협 여부 판단이 불가하고 또한 대응에 있어서도 조종사의 판단에 맡겨야 하며 대응을 하더라도 적절한 수단이 아닐 수 있다.
여기서는 아주 기본적인 머신 러닝 방법으로 역시 기본적인 레이다 파라미터를 학습한다.
그리고 학습된 모델은 임의의 신호를 넣었을 때에 그게 위협인지 아닌지 결과를 판단하는 것에 대해 알아본다.
이는 사실, 이전에 다른 포스트에서 머신 러닝에 대해서 정리했던 것에서 데이터만 바뀐것이라 할 수 있다.
또한, 머신 러닝 이론이나 인공지능에 자체에 대해서는 잘 모르기 때문에 이부분이 궁금하면 다른 포스트를 참고하고 여기서는 그냥 전체적인 흐름만 정리하였다.
임의의 레이다 파라미터 파일 생성
우선 학습을 할 CSV 파일 포멧의 임의의 레이다 파라미터가 필요하며 다음의 코드로 이를 랜덤 하게 만들 수 있다.
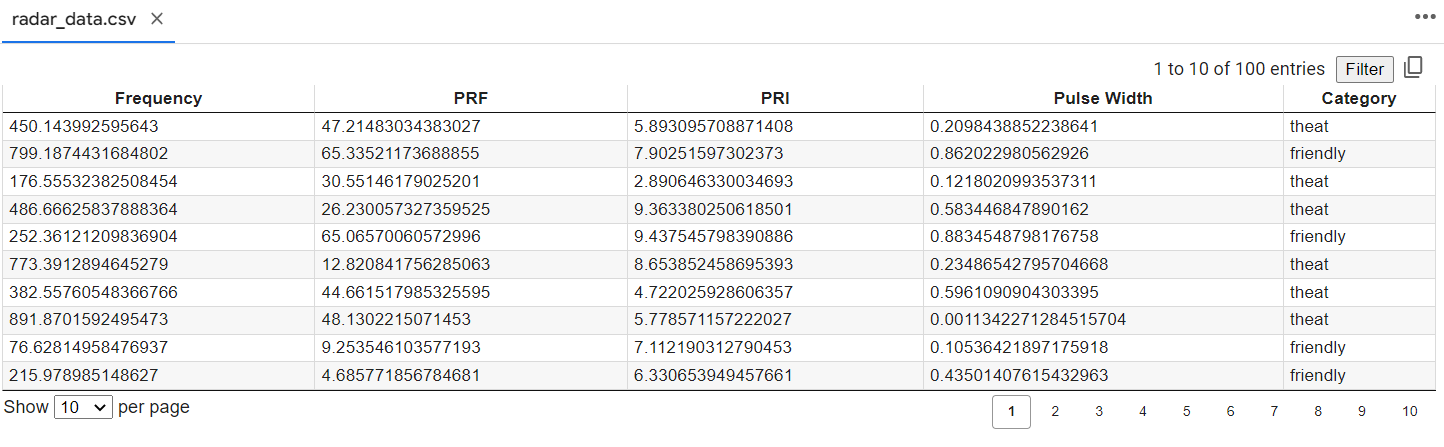
레이다 파라미터는 기본적인 주파수와 PRF, PRI, 펄스폭 정도만 설정하였고 마지막 column은 위협의 여부를 담을 Category이다.
import csv
import random
header = ['Frequency', 'PRF', 'PRI', 'Pulse Width', 'Category']
data = []
# Generate random radar data
for i in range(100):
row = [random.uniform(0, 1000), random.uniform(0, 100), random.uniform(0, 10), random.uniform(0, 1)]
if 10.0 < row[1] < 50.0:
row.append('theat')
else:
row.append('friendly')
data.append(row)
# Write data to CSV file
with open('radar_data.csv', 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(header)
writer.writerows(data)임의의 레이다 파라미터 중에서 위협의 신호로 구분을 짓기 위해 여기서는 PRF가 50보다 작은 경우를 위협(threat)으로 구분하고 그 외는 위협이 아닌(friendly) 신호로 구분하였다.
마지막 부분은 생성된 레이다 파라미터 데이터를 CSV 파일로 생성하는 내용이다.
이렇게 생성된 파일은 다음과 같은 형태이다.
머신 러닝 파이썬 코드
다음은 기계학습을 수행하는 파이썬 코드이다.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import KFold학습은 Scikit-Learn의 RandomForestClassifier 기능과 KFold 기능을 이용하며 이에 대한 좀 더 상세한 내용은 다른 블로그에 많이 있으므로 그것을 참조하길 바란다.
다음의 코드는 학습을 위해 앞에서 생성한 데이터(CSV파일)를 불러오고 레이다 파라미터 부분과 위협 여부 부분(Category)을 분리하여 X와 y에 저장한다.
# Load data from CSV file
data = pd.read_csv('radar_data.csv')
# Split data into features and labels
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
# Initialize random forest classifier
clf = RandomForestClassifier()그리고 random forest classifier 기능을 실행한다.
여기서는 Scikit-Learn의 KFold 기능을 이용한 교차 검증(cross-validation)을 통해 학습의 질을 높인다.
KFold 기능을 이용하여 5개의 fold로 데이터를 쪼갠 후 각 fold에 대해 학습을 수행한다.
shuffle은 데이터 내의 순서를 섞어서 샘플링할지 여부를 결정하고 'True'는 섞어서 샘플링하겠다는 것이다.
그리고 random_state는 seed를 설정한다.
역시 이에 대한 더욱 상세한 내용은 다른 블로그를 참고하길 바란다.
# Set up K-fold cross-validation
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
# Loop over each fold
fold_accuracy = []
for train_index, test_index in kfold.split(X):
X_train, X_test = X.iloc[train_index], X.iloc[test_index]
y_train, y_test = y.iloc[train_index], y.iloc[test_index]
# Fit the model on the training data
clf.fit(X_train, y_train)
# Make predictions on the test data
y_pred = clf.predict(X_test)
# Calculate accuracy for this fold and add to list of fold accuracies
fold_accuracy.append(accuracy_score(y_test, y_pred))
# Calculate the mean accuracy across all folds
mean_accuracy = sum(fold_accuracy) / len(fold_accuracy)
print("Mean accuracy:", mean_accuracy)위의 코드에서 학습은 fit 매소드를 통해 수행되며 predict 매소드를 통해 예측을 수행한다.
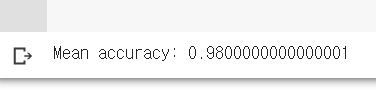
위의 코드에는 정확도를 확인하는 부분을 추가하였는데, sklearn.matrics의 accuracy_score 기능을 통해 각 fold의 정확도를 평가하고 전 fold의 정확도를 평균하여 출력한다.
다음의 코드는 학습된 모델에 새로운 레이다 파라미터가 입력되었을 때 위협 여부를 예측하는 기능을 정의한 것이다.
def predict(frequency, prf, pri, pulse_width):
X = [[frequency, prf, pri, pulse_width]]
prediction = clf.predict(X)
return prediction[0]
결과 확인
위까지 코드를 실행하면 현재 모델의 정확도가 아래와 같이 출력된다.
확인하려는 레이다 파라미터는 다음과 같이 입력하면 학습된 모델은 위협 여부를 출력해 준다.

위는 PRF에 70을 입력한 경우이며 50보다 크기 때문에 위협이 아니고 결과도 동일하게 출력되었다.
이번에는 PRF에 30을 입력하는 경우이다.
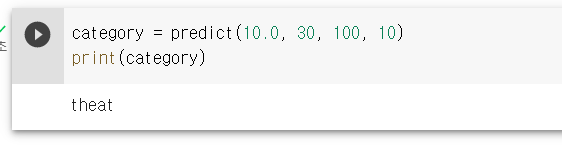
결과는 예측대로 위협으로 출력된다.
여기서 더 나아가 애매한 경계의 숫자를 입력해 본다.
PRF에 49.4까지는 위협으로 정상 판단하나 다음과 같이 49.5 이상을 넣으면 friendly로 판단하는 것을 볼 수 있다.
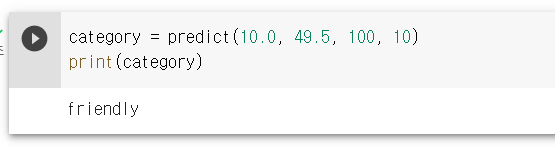
입력 PRF 값이 50보다 작지만 threat으로 판단하지 못한 것은 앞에서 확인했듯이 이 모델의 정확도가 98% 수준이고 그렇기 때문에 소수점 자릿수에서 정확하지 않는 것으로 보인다.
모델의 정확도는 여러 가지 방법으로 높일 수 있는데 이 부분에는 전문적이지 못하기 때문에 다루지 않겠다.
마치며...
아주 간단한 머신 러닝 방법으로 기본적인 임의의 레이다 파라미터를 학습시키고 새로운 파라미터를 입력했을 때 위협인지 아닌지를 판단하는 로직에 대해 간략히 정리하였다.
Cognitive EW는 이렇듯 신호의 다양한 형태와 환경을 학습한 모델을 적용하여 정의되지 않은 새로운 신호를 수신하였을 때에 실시간으로 위협의 가능성을 판단하고 이에 대한 대응 방법까지 알아낸다고 한다.
미국에서 개발하는 전자전 장비에 이러한 머신 러닝 방법과 인공지능이 적용되었다는데 그 수준이 어느 정도인지는 확인할 수가 없다.
우리나라도 빨리 이러한 기술이 적용되면 좋을 것 같다.
그렇지만 그전에 모델을 학습시킬 수 있는 신뢰도 높은 데이터 베이스의 확보가 우선일 것 같다.
'Python' 카테고리의 다른 글
| ChatGPT API를 이용한 간단한 챗봇 만들기 (0) | 2023.07.02 |
|---|---|
| 로또 번호 생성기 & ChatGPT (0) | 2023.01.07 |
| 파이썬을 이용한 자동 거래 - RSI Divergence 수익 분석 (8) | 2023.01.01 |
| 파이썬을 이용한 가상화폐 자동거래 - RSI Divergence (update) (0) | 2022.12.19 |
| 파이썬을 이용한 RSI Divergence 구현 (7) | 2022.11.19 |




댓글